User guide¶
Key concepts¶
The baikal API introduces three basic elements:
Step: Steps are the building blocks of the API. Conceptually similar to TensorFlow’s operations and Keras layers, each Step is a unit of computation (e.g. PCA, Logistic Regression) that take the data from preceding Steps and produce data to be used by other Steps further in the pipeline. Steps are defined by combining the
Stepmixin class with a base class that implements the scikit-learn API. This is explained in more detail below.DataPlaceholder: The inputs and outputs of Steps. If Steps are like TensorFlow operations or Keras layers, then DataPlaceHolders are akin to tensors. Don’t be misled though, DataPlaceholders are just minimal, low-weight auxiliary objects whose main purpose is to keep track of the input/output connectivity between steps, and serve as the keys to map the actual input data to their appropriate Step. They are not arrays/tensors, nor contain any shape/type information whatsoever.
Model: A Model is a network (more precisely, a directed acyclic graph) of Steps, and it is defined from the input/output specification of the pipeline. Models have fit and predict routines that, together with graph-based engine, allow the automatic (feed-forward) computation of each of the pipeline steps when fed with data.
Quick-start guide¶
Without further ado, here’s a short example of a simple SVC model built with baikal:
import sklearn.svm
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from baikal import make_step, Input, Model
# 1. Define a step
SVC = make_step(sklearn.svm.SVC)
# 2. Build the model
x = Input()
y_t = Input()
y = SVC(C=1.0, kernel="rbf", gamma=0.5)(x, y_t)
model = Model(x, y, y_t)
# 3. Train the model
dataset = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
dataset.data, dataset.target, random_state=0
)
model.fit(X_train, y_train)
# 4. Use the model
y_test_pred = model.predict(X_test)
API walkthrough¶
As shown in the short example above, the baikal API consists of four basic steps:
Let’s take a look at each of them in detail. Full examples can be found in the project’s examples folder.
1. Define the steps¶
A step is defined very easily, just feed the provided make_step function with the
class you want to make a step from:
import sklearn.linear_model
from baikal import make_step
LogisticRegression = make_step(sklearn.linear_model.LogisticRegression)
You can make a step from any class you like, so long that class implements the scikit-learn API.
What this function is doing under the hood, is to combine the given class with the Step
mixin class. The Step mixin, among other things, endows the given class with a
__call__ method, making the class callable on the outputs (DataPlaceholder objects)
of previous steps. If you prefer to do this manually, you only have to:
Define a class that inherits from both the
Stepmixin and the class you wish to make a step of (in that order!).In the class
__init__, callsuper().__init__(...)and pass the appropriate step parameters.
For example, to make a step for sklearn.linear_model.LogisticRegression we do:
import sklearn.linear_model
from baikal import Step
# The order of inheritance is important!
class LogisticRegression(Step, sklearn.linear_model.LogisticRegression):
def __init__(self, *args, name=None, n_outputs=1, **kwargs):
super().__init__(*args, name=name,n_outputs=n_outputs,**kwargs)
Other steps are defined similarly (omitted here for brevity).
baikal can also handle steps with multiple input/outputs/targets. The base class may
implement a predict/transform method (the compute function) that take multiple
inputs and returns multiple outputs, and a fit method that takes multiple inputs and targets
(native scikit-learn classes at present take one input, return one output, and take at
most one target). In this case, the input/target arguments are expected to be a list of
(typically) array-like objects, and the compute function is expected to return a list of
array-like objects. For example, the base class may implement the methods like this:
class SomeClass(BaseEstimator):
...
def predict(self, Xs):
X1, X2 = Xs
# use X1, X2 to calculate y1, y2
return y1, y2
def fit(self, Xs, ys):
(X1, X2), (y1, y2) = Xs, ys
# use X1, X2, y1, y2 to fit the model
return self
2. Build the model¶
Once we have defined the steps, we can make a model like shown below. First, you create
the initial step, that serves as the entry-point to the model, by calling the Input
helper function. This outputs a DataPlaceholder representing one of the inputs to the
model. Then, all you have to do is to instantiate the steps and call them on the outputs
(DataPlaceholders from previous steps) as you deem appropriate. Finally, you instantiate
the model with the inputs, outputs and targets (also DataPlaceholders) that specify your
pipeline.
This style should feel familiar to users of Keras.
Note that steps that require target data (like ExtraTreesClassifier, RandomForestClassifier,
LogisticRegression and SVC) are called with two arguments. These arguments correspond
to the inputs (e.g. x1, x2) and targets (e.g. y_t) of the step. These targets
are specified to the Model at instantiation via the third argument. baikal pipelines
are made of complex, heterogenous, non-differentiable steps (e.g. a whole RandomForestClassifier,
with its own internal learning algorithm), so there’s no some magic automatic differentiation
that backpropagates the target information from the outputs to the appropriate steps, so
we must specify which step needs which targets directly.
from baikal import Input, Model
from baikal.steps import Stack
# Assume the steps below were already defined
x1 = Input()
x2 = Input()
y_t = Input()
y1 = ExtraTreesClassifier()(x1, y_t)
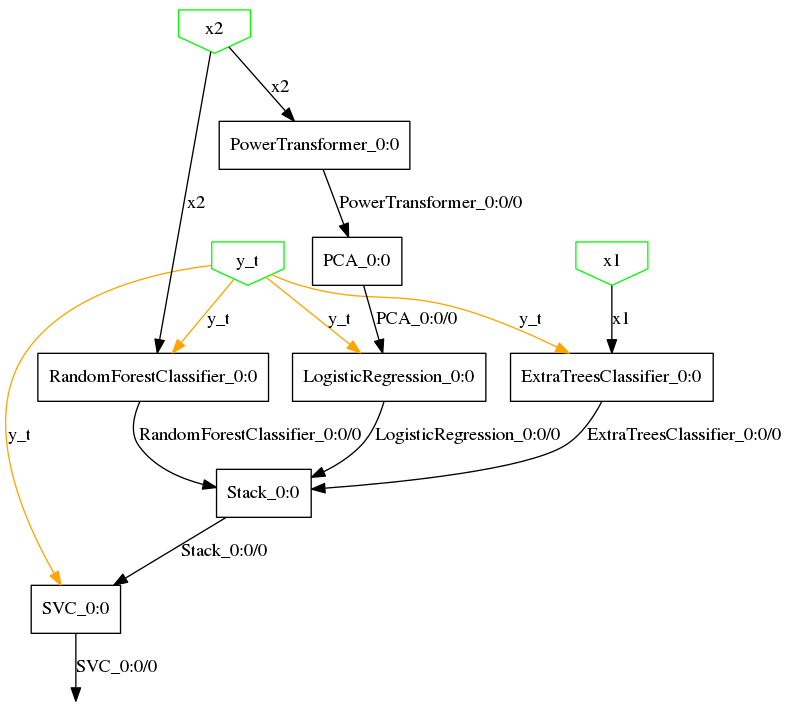
y2 = RandomForestClassifier()(x2, y_t)
z = PowerTransformer()(x2)
z = PCA()(z)
y3 = LogisticRegression()(z, y_t)
ensemble_features = Stack()([y1, y2, y3])
y = SVC()(ensemble_features, y_t)
model = Model([x1, x2], y, y_t)
You can call the same step on different inputs and targets to reuse the step (similar to
the concept of shared layers and nodes in Keras), and specify a different compute_func/trainable
configuration on each call. This is achieved via “ports”: each call creates a new port
and associates the given configuration to it. You may access the configuration at each
port using the get_*_at(port) methods.
(*) Steps are called on and output DataPlaceholders. DataPlaceholders are produced and consumed exclusively by Steps, so you do not need to instantiate these yourself.
3. Train the model¶
Now that we have built a model, we are ready to train it. The model also follows the
scikit-learn API, as it has a fit method:
model.fit(X=[X1_train, X2_train], y=y_train)
-
baikal.Model.fit(self, X, y=None, **fit_params) Trains the model on the given input and target data.
The model will automatically propagate the data through the pipeline and fit any internal steps that require training.
- Parameters
X –
Input data (independent variables). It can be either of:
A single array-like object (in the case of a single input)
A list of array-like objects (in the case of multiple inputs)
A dictionary mapping DataPlaceholders (or their names) to array-like objects. The keys must be among the inputs passed at instantiation.
y –
Target data (dependent variables) (optional). It can be either of:
None (in the case all steps are either non-trainable and/or unsupervised learning steps)
A single array-like object (in the case of a single target)
A list of array-like objects(in the case of multiple targets)
A dictionary mapping target DataPlaceholders (or their names) to array-like objects. The keys must be among the targets passed at instantiation.
Targets required by steps that were set as non-trainable might be omitted.
fit_params – Parameters passed to the fit method of each model step, where each parameter name has the form
<step-name>__<parameter-name>.
4. Use the model¶
To predict with the model, use the predict method and pass it the input data like you
would for the fit method. The model will automatically propagate the inputs through
all the steps and produce the outputs specified at instantiation.
y_test_pred = model.predict([X1_test, X2_test])
# This also works:
y_test_pred = model.predict({x1: X1_test, x2: X2_test})
-
baikal.Model.predict(self, X, output_names=None) Predict by applying the model on the given input data.
- Parameters
X – Input data. It follows the same format as in the
fitmethod.output_names – Names of required outputs (optional). You can specify any final or intermediate output by passing the name of its associated data placeholder. This is useful for debugging. If not specified, it will return the outputs specified at instantiation.
- Returns
array-like or list of array-like – The computed outputs.
Models are query-able. That is, you can request other outputs other than those specified
at model instantiation. This allows querying intermediate outputs and ease debugging.
For example, to get both the output from PCA and the ExtraTreesClassifier:
outs = model.predict(
[X1_test, X2_test], output_names=["ExtraTreesClassifier_0:0/0", "PCA_0:0/0"]
)
You don’t need to pass inputs that are not required to compute the queried output.
For example, if we just want the output of PowerTransformer:
outs = model.predict({x2: X2_data}, output_names="PowerTransformer_0:0/0")
Models are also nestable. In fact, Models are steps, too. This allows composing smaller models into bigger ones, like so:
# Assume we have two previously built complex
# classifier models, perhaps loaded from a file.
submodel1 = ...
submodel2 = ...
# Now we make an stacked classifier from both submodels
x = Input()
y_t = Input()
y1 = submodel1(x)
y2 = submodel2(x, y_t)
z = Stack()([y1, y2])
y = SVC()(z, y_t)
bigmodel = Model(x, y, y_t)
Generalizations introduced by the API¶
The baikal API generalizes scikit-learn estimators and pipelines in several ways:
Steps can be combined into non-linear pipelines. That is,
steps may be parallel,
feed-forward connections my exist between non-consecutive steps,
an input of the pipeline is not necessarily taken from the first step,
an output of the pipeline is not necessarily produced from the last step.
Steps can take multiple inputs and produce multiple outputs. This, for example, is useful for defining steps for aggregating, concatenating or splitting arrays; building models that take multi-modal data, for example and input for an image, and an input for tabular data; and building models with mixed classification/regression outputs.
Steps can lack a fit method. Models allow steps that have no fit method
(a.k.a. stateless estimators). At training time, such steps will omit their own training
and simply do inference on their inputs to produce the outputs required by successive
steps.
Also, the Model graph engine will, for each step, pass only the arguments associated to
the inputs and targets that were specified for that step. So, if you (naturally) didn’t
specify any targets for an unsupervised step, then that step can safely define a fit
method with a fit(X) signature. This avoids having to define methods with a
misleading fit(X, y=None) signature if the step either does not require target data
or does not require a fit method at all, improving the readability of estimator classes.
In short, this means steps can
omit defining
fitfor stateless steps,define
fit(X)for unsupervised steps,define
fit(X, y)for supervised and semi-supervised steps.
Steps can specify any function for inference. Canonical scikit-learn estimators
typically define either a predict or a transform method as their function for
inference, and the Pipeline API only admits these two. More complex
models, however, may require estimators that do other kinds of computations such as
prediction probabilities, the decision function, or the leaf indices of decision tree
predictions. To allow this, the Step API generalizes these as “compute functions” and
provides a compute_func argument that can be used to specify predict_proba ,
decision_function , apply or any other function for inference.
Steps can be frozen. This is done via a trainable boolean flag and allows you
to skip steps during training time. This is useful if you have a pre-trained estimator
that you would like to reuse in another model without re-training it when training the
whole model.
Steps can specify special behavior at training time. Some estimators define special
fit_transform or fit_predict methods that do both training and inference in a
single swoop. Usually, such methods are meant to leverage implementations that are more
efficient than calling fit and predict/transform separately, or meant for
transductive estimators as such estimators don’t allow separate training and inference
regimes. From the perspective of the execution of a pipeline at training time, where
training and inference (to produce the outputs required by successor steps) is done for
each step in tandem, these methods can be generalized to provide a means to control
these stages jointly and define special behaviors. This can be useful, for example, for
implementing training protocols such as that of stacked classifiers, where the
classifiers in the first stage are trained on the input data, but instead compute
out-of-fold predictions for the next stage in the stack. The Step API provides this via
a fit_compute_func argument which, if specified, will be used by the graph execution
instead of using fit and compute_func separately.
Steps can be shared. Steps can be called on different inputs and targets (similar to
the concept of shared layers and nodes in Keras), and specify a different behavior (that
is, a specific configuration of compute_func, fit_compute_func and trainable),
on each call. The mapping between inputs/targets and the behavior is achieved via
“ports”: each call creates a new port on the step and associates the given configuration
to the inputs/targets the step was called on. The Model graph engine will then use the
appropriate configuration on each set of inputs and targets.
Shared steps allow reusing a step and its learned parameters on different inputs. For example, this is particularly useful for reusing learned transformations on targets. Also, this useful for reusing steps of stateless estimators to apply the same computation (e.g. casting data types, dropping dimensions) on several inputs.
Utilities¶
Persisting the model¶
Like native scikit-learn objects, models can be serialized with pickle or joblib without any extra setup:
import joblib
joblib.dump(model, "model.pkl")
model_reloaded = joblib.load("model.pkl")
Keep in mind, however, the security and maintainability limitations of these formats.
scikit-learn wrapper for GridSearchCV¶
Currently, baikal also provides a wrapper utility class that allows models to used in scikit-learn’s GridSearchCV API. Below there’s a code snippet showing its usage. It follows the style of Keras’ own wrapper.
See Tune a model with GridSearchCV for an example script of this utility.
A future release of baikal plans to include a custom GridSearchCV API, based on
the original scikit-learn implementation, that can handle baikal models natively, avoiding
a couple of gotchas with the current wrapper implementation (mentioned below).
# 1. Define a function that returns your baikal model
def build_fn():
x = Input()
y_t = Input()
h = PCA(random_state=random_state, name="pca")(x)
y = LogisticRegression(random_state=random_state, name="classifier")(h, y_t)
model = Model(x, y, y_t)
return model
# 2. Define a parameter grid
# - keys have the [step-name]__[parameter-name] format, similar to sklearn Pipelines
# - You can also search over the steps themselves using [step-name] keys
param_grid = [
{
"classifier": [LogisticRegression()],
"classifier__C": [0.01, 0.1, 1],
"pca__n_components": [1, 2, 3, 4],
},
{
"classifier": [RandomForestClassifier()],
"classifier__n_estimators": [10, 50, 100],
},
]
# 3. Instantiate the wrapper
sk_model = SKLearnWrapper(build_fn)
# 4. Use GridSearchCV as usual
gscv_baikal = GridSearchCV(sk_model, param_grid)
gscv_baikal.fit(x_data, y_data)
best_model = gscv_baikal.best_estimator_.model
Currently there are a couple of gotchas:
The
cvargument ofGridSearchCVwill default to KFold if the estimator is a baikal Model, so you have to specify an appropriate splitter directly if you need another splitting scheme.GridSearchCVcannot handle models with multiple inputs/outputs. A way to work around this is to split the input data and merge the outputs within the model.
Plotting your model¶
The baikal package includes a plot utility.
from baikal.plot import plot_model
plot_model(model, filename="model.png")
In order to use the plot utility, you need to install pydot and graphviz.
For the example above, it produces this: